Teaching Culper to Learn: NER Training Is Live
One of the core promises behind Project Culper is that the system should get smarter over time. Not just smarter in a general sense, but smarter about your organization’s intelligence data. This week, we shipped the feature that makes that possible: on-demand NER (Named Entity Recognition) training.
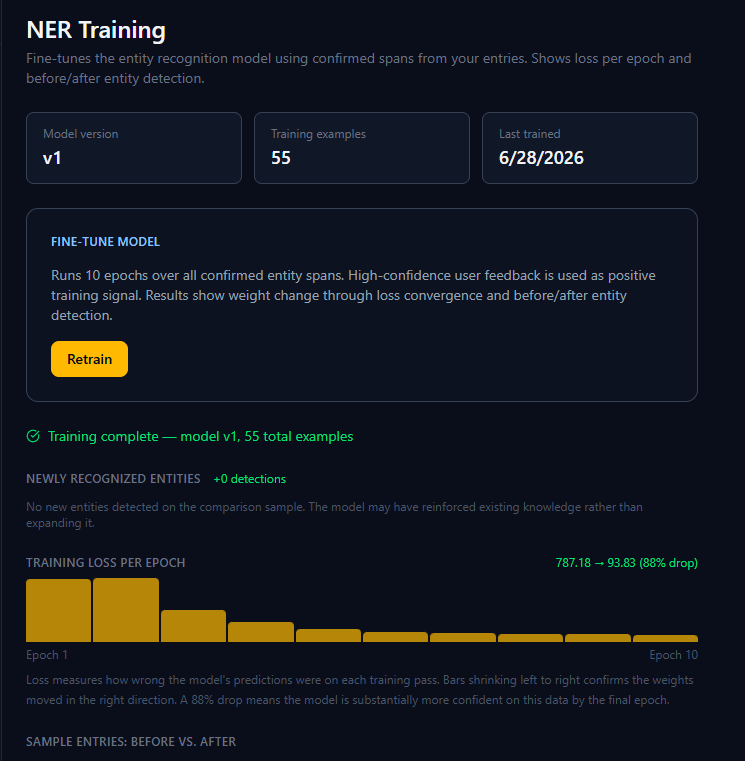
Here is how it works. Analysts have been reviewing entries and confirming entity spans, deciding which names and locations the system correctly identified and which ones it missed or mislabeled. Every confirmed span is a data point. When an analyst hits “Train,” a Celery background job collects all those human-validated examples, formats them into spaCy training data, ships them to the NER microservice, and kicks off a fine-tuning run against the base en_core_web_lg model.
The Training dashboard gives you live feedback on the run: a loss curve that drops epoch by epoch, a before-and-after sample showing how the model’s predictions changed, and a summary of the new entity types it picked up. A 40% drop in training loss over ten epochs is not just a number; it is a measurable signal that the model is closing the gap between its defaults and the language your analysts actually use.
The architecture keeps this isolated per tenant. Every org trains its own model instance, so one organization’s data never bleeds into another’s predictions. When training finishes, the updated weights load automatically, and the next entity extraction call uses them.
The loop is closed. Analyst corrections now feed directly back into the intelligence engine.
