CSV Import and Dynamic Entry Types
One of the feedback points I kept coming back to during planning was this: field intelligence tools live or die by how easy it is to get data in. If migrating from a legacy system means manually re-entering hundreds of incident reports, nobody is switching. This week I built out a proper CSV import pipeline to solve that.
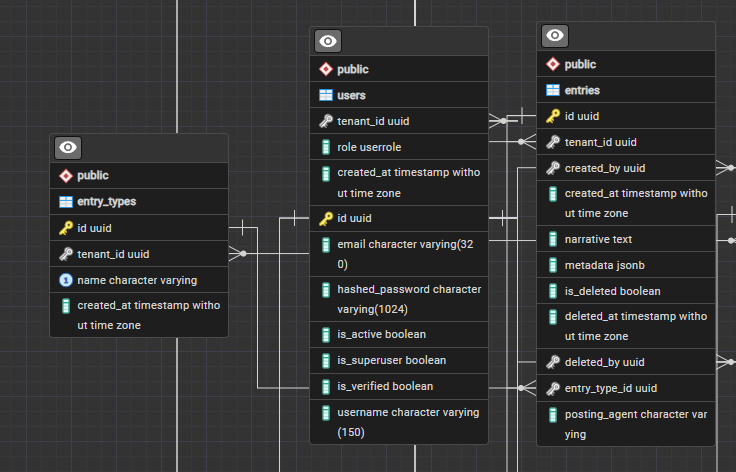
The biggest structural change was retiring the hardcoded entry_type enum. Previously, entries could only be classified as incident, observation, or patch note, and those values were baked into a PostgreSQL enum column. That works fine when you control the vocabulary, but it breaks the moment you try to import data from a system that calls things “field contact” or “suspicious activity report.” The enum is now a proper entry_types table. System types still exist as shared rows with a null tenant ID, and tenants can define their own types freely. When you run an import, any type value found in the CSV that does not already exist gets created on the fly for that tenant.
The import endpoint itself takes a CSV file and a small JSON mapping config that names which columns correspond to posting agent, narrative, and datetime. Everything else in the CSV goes straight into the entry’s metadata JSONB field as custom fields. Datetimes are parsed with timezone support so historical records from another system come in with their original timestamps intact. The whole import is all-or-nothing: one bad row rolls back the entire batch.
A username field also landed on the user model this sprint, and posting_agent on entries lets imports carry the original author string without needing a user account in Culper for every name in the source data.
